Naming things is a crucial aspect of software design in general. As such, it's very hard to immediately see its value and very tempting to avoid spending any time or mental energy at all on it.
There are only two hard things in Computer Science: cache invalidation and naming things.1
Only people who have had to work on old code bases written hastily by other developers that are no longer around, or in some cases even their own personal projects stalled not so long ago, have felt the pain associated with reading source code and wondering what the hell it does and if it's even doing what it should.
The return of the time and effort invested in naming things as clearly as possible is most easily perceived in the long run. But it's usually when it's missing that it's noticeable the most.
One small real life example
The common case where a user signs up using their email address and a password. The application requests that the user proves they can access the emails in that address - that they actually own it, to prevent typos or possible spam attacks.
We go ahead and implement this feature. Easy-peasy. Pick a transactional email provider, create a JWT or some other token, send it to the user in an email and expect it back at an endpoint, which will set user.verified to true.


The length of a variable name should be proportional to the enclosing scope. Small scope, short name.
The length of function and class names should be inversely proportional to the enclosing scope.
Fast-forward a few months and the product team request a new feature: the ability to offer certain platform features to users that own at least 1000 POE, an ERC-20 token.
This can be achieved in two steps:
- First, request that the user provides proof they own a certain Ethereum address.
- Second, retrieve the account's POE balance and check that it's least 1000.
The first step only needs to happen once. As with the email verification, we can store the result of this process in the user's account in the database.
We have to pick a name for this new field. But whatever we choose, there will always be ambiguity with the previous user.verified field. What does it mean for a user to be verified? Does it mean they have verified their account in every possible way? What happens if we need to add other types of verification, such as providing a selfie holding an ID, as most cryptocurrency exchanges do?
If we name our new field poeVerified, we may wind up seeing code like this:
if (account.verified && !account.poeVerified)
doThis()
else if (!account.verified)
doThat()Making a change to this code would require inferring the meaning of verified, which will usually lead to a search for references in the entire codebase.
Simply naming the field emailVerified rather than just verified would be enough to fix the issue (no need to go as far as proofOfEmailAccessProvided, but I won't judge you if you do). But renaming things can be expensive. Especially if we're talking about a database field.
This example is trivial, but these problems tend to snowball and only become noticeable when they have been impacting the effort needed by the team to push forward features and fixes; slowing the developers down and draining their mental energy, which in turn reduces motivation.

There are two hard things in computer science: cache invalidation, naming things, and off-by-one errors.
The problem
The issue arises from a combination of lack of anticipation with the general rule to avoid overengineering.
We learn not to overengineering things, making systems more complex than they need be. This is with good reason, as time to market is in many cases more critical to the survival of a start up than not accumulating technical debt.
It's very hard to anticipate how the system will evolve over time. Foreseeing how we may need to update the code base is a skill that can only be learned from experience.

Lousy variable name: data
It says nothing about what's inside.
It's surprising how often I see this in code. It's especially problematic in dynamic languages like JavaScript, because there's no type system to lean on.
A good variable name helps me understand at a glance.
Finding a balance between over and underengineering can be hard, and the pressure from users or the product or marketing teams to release as fast as possible usually pushes the more novice developers to write code that barely works, let alone follow best practices.
There's also a game-theoretical element to this. In bigger companies, as with the prisoner's dilemma, if one software developer is more likely to receive reward for a faster implementation and no punishment for lowering the overall code quality, there'll be a natural tendency towards ignoring more and more elements of software architecture, until the development speed lowers almost to a halt and the whole thing needs to be rewritten.
In this sense, code quality is akin to the commons in the tragedy of the commons.
The solution
Here's a simple rule of thumb:
The less contained the thing you're trying to name is, the more critical it is to name it well.
For example, suppose we need to define a function that calculates the distance between two points in the plane:
const distance = (point1, point2) =>
Math.sqrt((point1.x - point2.x) ** 2 + (point1.y - point2.y) ** 2) Here we don't need to give very special names to the arguments, they are only used in a single line of code. Even p1 and p2 could do.
And if we are using a type system, such as TypeScript, we could simplify the names further:
const distance = (a: Point, b: Point) =>
Math.sqrt((a.x - b.x) ** 2 + (a.y - b.y) ** 2) To give a more thorough example, if we wanted to break down this function into imperative steps:
const distance = (point1, point2) => {
const a = (point1.x - point2.x)
const b = (point1.y - point2.y)
return Math.sqrt(a ** 2, b ** 2)
} Here we're naming our constants just plain a and b. It's not descriptive, but it doesn't matter much since it's easy to infer what's going on from the code.
On the other hand, if we find ourselves needing to name a database field, a class or writing a more complex function (for example, one that verifies that a cryptographic signature generated from an Ethereum address and private key is correct), we'll want to pay closer attention to the names we pick.
import { bufferToHex, ecrecover, fromRpcSig, hashPersonalMessage, publicToAddress } from 'ethereumjs-util'
export function signatureIsValid(address: string, message: string, signature: string): boolean {
if (!address || !signature)
return false
try {
const messageHash = hashPersonalMessage(Buffer.from(message))
const signatureParams = fromRpcSig(signature)
const publicKey = ecrecover(
messageHash,
signatureParams.v,
signatureParams.r,
signatureParams.s,
)
const recoveredAddressBuffer = publicToAddress(publicKey)
const recoveredAddress = bufferToHex(recoveredAddressBuffer)
return recoveredAddress.toLowerCase() === address.toLowerCase()
} catch (exception) {
if (exception.message === 'Invalid signature length')
return false
else if (exception.message === 'couldn\'t recover public key from signature')
return false
else
throw exception
}It boils down to intention
One of the root problems is that we often find code that should be doing one thing, but does another: it has a bug 🐛! In those cases we're forced not only to read the code and understand what it is doing, but also what the original programmer intended it to do.
In a stack overflow question asking what the single most important factor for writing maintainable code is, the number one answer was:
Write it for other people to read. This means a combination of good names, good comments, and simple statements.
Giving descriptive names to variables, constants, functions, etc, helps us infer the intention the programmer had for this code when they wrote it.
Let's go back to our first real life example: allowing users who have proven they own at least 1000 POE tokens to upload files.
const postArchive = async (account, file, size) => {
if (size > msize)
throw new SizeError(size, msize)
const { address, verified } = account
if (!verified)
throw new VerifiedError()
const b = await token.getBalance(address)
const balance = b / Math.pow(10, decimals)
if (balance < min)
throw new BalanceError(min, balance)
return upload(file)
}Here we're referencing that are defined outside of the function scope, such as msize. We can't easily infer the purpose of that or what values it could have from its name. If there was a bug in this code, we also couldn't rely on the code itself to infer the intention the programmer had.
We'd be left with one choice: we'll have to navigate the code, look for the definition of msize and try to find places it gets a value assigned.
The same can be said about the errors being thrown or other constant names: none of them help much to understand what the code is intended to do.
Here, more verbosity helps infer intention:
const postArchive = async (account, file, network, fileSize) => {
if (fileSize > maximumFileSizeInBytes)
throw new FileTooBig(fileSize, maximumFileSizeInBytes)
const { poeAddress, poeAddressVerified } = account
if (!poeAddressVerified)
throw new PoeAddressNotVerified()
const poeBalance = await poeContract.getBalance(poeAddress)
const poeBalanceWithDecimals = poeBalance / Math.pow(10, poeContractDecimals)
if (poeBalanceWithDecimals < poeBalanceMinimum)
throw new PoeBalanceInsufficient(poeBalanceMinimum, poeBalanceWithDecimals)
return upload(file)
}Code Review
So far, I've mentioned the cases in which one needs to read code written by somebody else to fix a bug or add a feature.
In reality, we are likely to spend more time reading somebody else's code when reviewing it then when working on it. A small team will probably submit a PR a day on average, and in most cases at least two other team members will be reviewing it. (If this is not a practice your team is following, I encourage you to start right now).
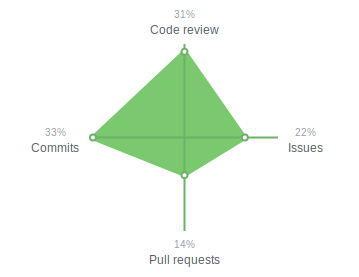
During 2018, I spent more time reviewing code than I did writing it. One of the things that consistently helped the entire team understand code and improve the code-review feedback loop was thoughtful naming of functions, constants, etc.
Conclusion
Although not a panacea to all code ailments, thoughtful naming of things is one of the key elements to having a codebase that's easy to read and improve, which leads to less bugs in production and faster development of new features.
- Phil Karlton, per David Karlton on skeptics.stackexchange.com